I am a third-year Ph.D. student in Computer Science at the Australian Institute for Machine Learning (AIML), University of Adelaide, fortunate to be supervised by Prof. Lingqiao Liu and Dr. Xinyu Zhang. Before that, I completed my Master’s degree in Machine Learning and Computer Vision at the Australian National University where I worked on multi-camera detection problems advised by Prof. Liang Zheng. My current research focuses on Generative World Models, 3D Generation, and Example-based Content Generation. I am currently doing a research internship at Alibaba Token Hub, working closely with Dr. Xinlong Wang and Fan Zhang.
I am on the job market for 2026 Fall (expected to graduate in early 2027) — feel free to reach out!
我正在参加 2026 年秋招,预计于 2027 年上半年毕业,欢迎联系!
Research Vision
My long-term goal is to build
controllable, consistent, and efficient world models that maintain:
- Faithful world state representations — spanning video frames, 3D structures, semantic interpretations, and high-dimensional embeddings
- Rich controllability beyond simple text prompts — enabling precise manipulation of world dynamics
- Long-term consistency across all modalities and dimensions
- Efficient state management for scalable simulation
News
Selected Publications
Generative World Modeling
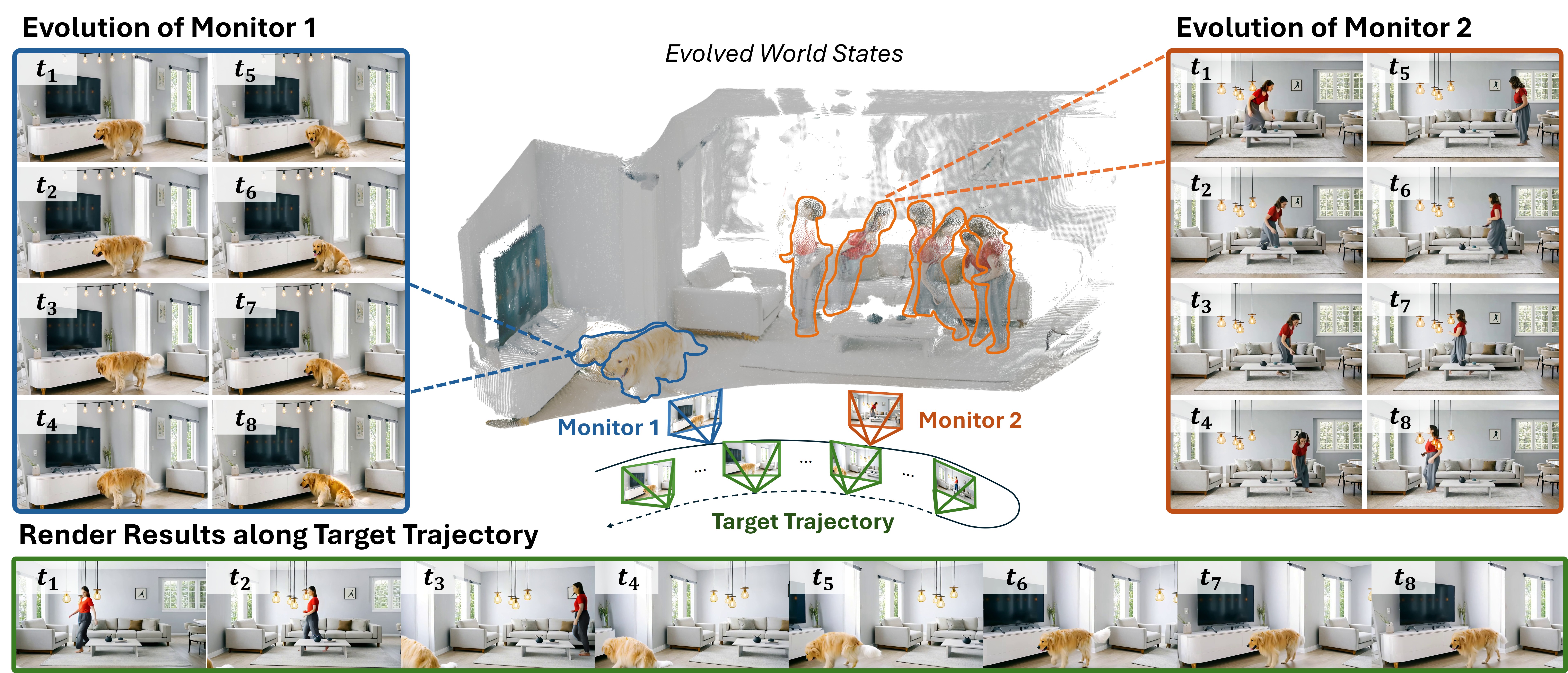
LiveWorld: Simulating Out-of-Sight Dynamics in Generative Video World Models Zicheng Duan*, Jiatong Xia*, Zeyu Zhang*, Wenbo Zhang, Gengze Zhou,
Chenhui Gou, Yefei He, Feng Chen, Xinyu Zhang, Lingqiao Liu
ECCV 2026 [
Demo Page /
Paper /
Code]
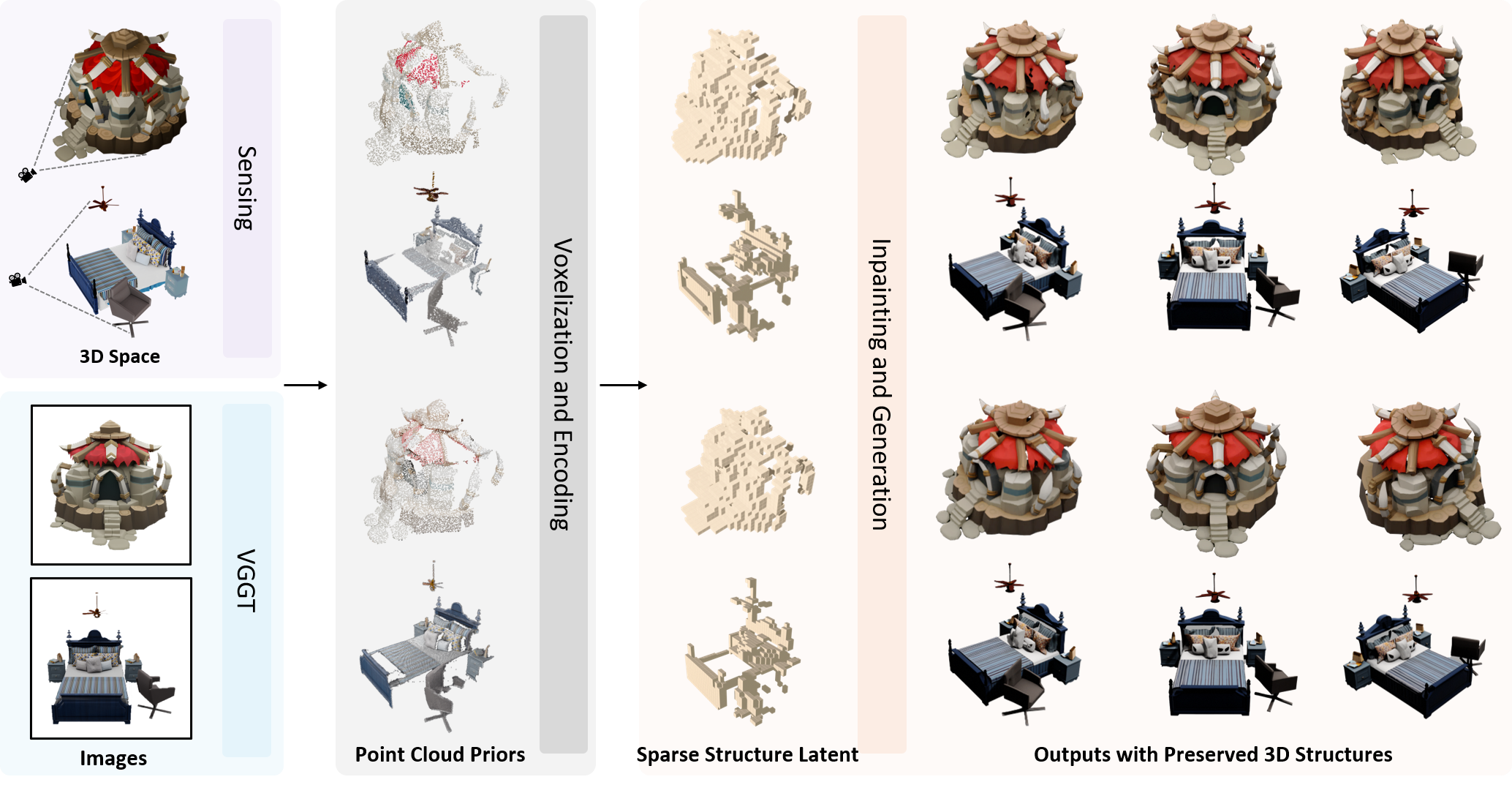
Points-to-3D: Structure-Aware 3D Generation with Point Cloud Priors Jiatong Xia*,
Zicheng Duan*, Anton van den Hengel, Lingqiao Liu
CVPR 2026 [
Demo Page /
Paper]
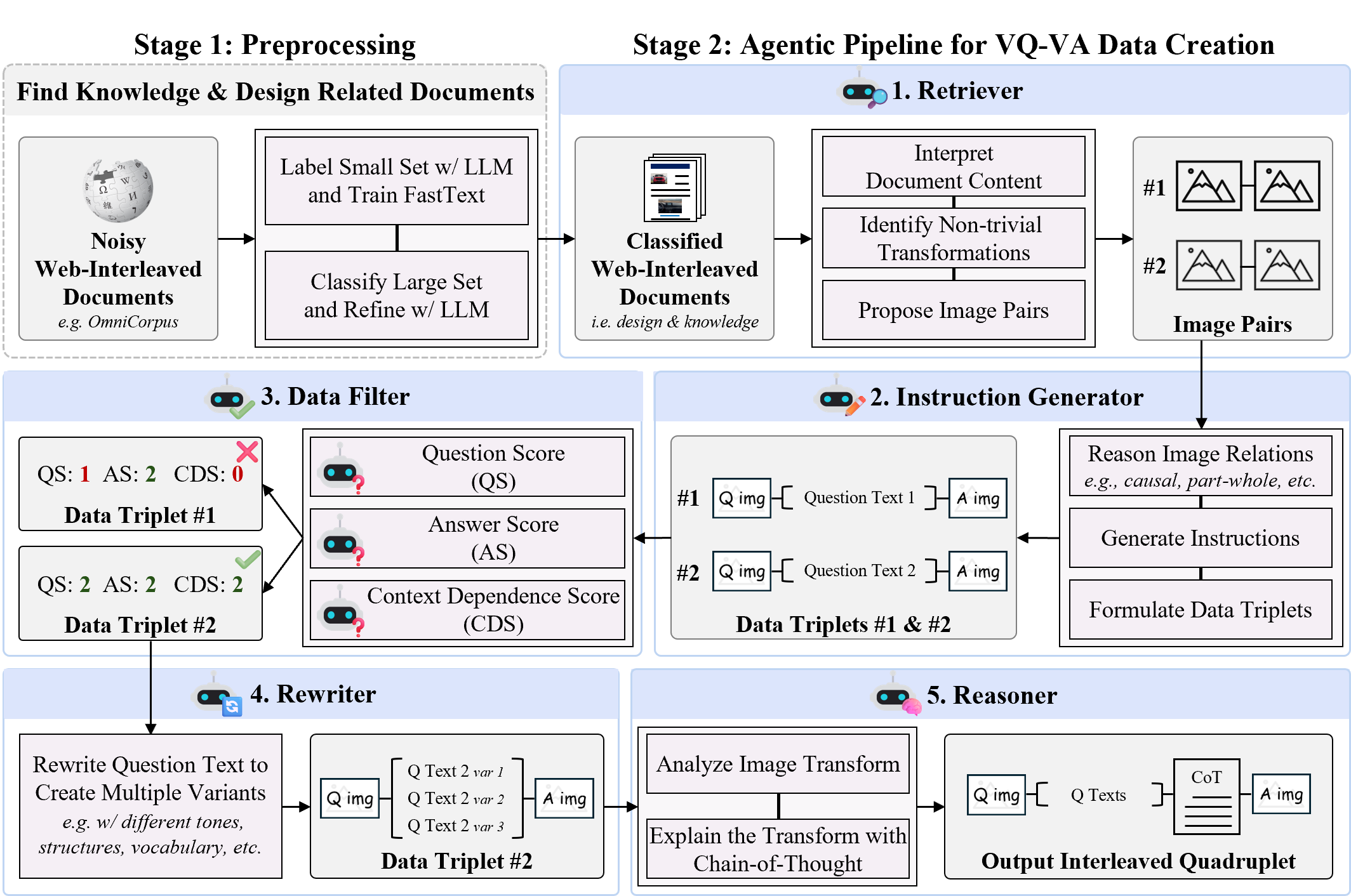
VQ-VA World: Towards High-Quality Visual Question-Visual Answering Chenhui Gou*, Zilong Chen*, Zeyu Wang*, Feng Li, Deyao Zhu,
Zicheng Duan, Kunchang Li, Chaorui Deng, Hongyi Yuan, Haoqi Fan, Cihang Xie, Jianfei Cai, Hamid Rezatofighi
CVPR 2026 [
Demo Page /
Paper]
Contrtollable Content Generation
EZIGen: Enhancing zero-shot personalized image generation with precise subject encoding and decoupled guidance Zicheng Duan, Yuxuan Ding, Chenhui Gou, Ziqin Zhou, Ethan Smith, Lingqiao Liu
BMVC 2025 [
Demo Page /
Paper /
Code]
Training-Free Motion-Guided Video Generation with Enhanced Temporal Consistency Using Motion Consistency Loss Xinyu Zhang,
Zicheng Duan, Dong Gong, Lingqiao Liu
BMVC 2025 [
Demo Page /
Paper]
Let Your Video Listen to Your Music! Xinyu Zhang, Dong Gong,
Zicheng Duan, Anton van den Hengel, Lingqiao Liu
ACM MM 2025 [
Demo Page /
Paper]
All Publications (click to expand)
LiveWorld: Simulating Out-of-Sight Dynamics in Generative Video World Models Zicheng Duan*, Jiatong Xia*, Zeyu Zhang*, Wenbo Zhang, Gengze Zhou,
Chenhui Gou, Yefei He, Feng Chen, Xinyu Zhang, Lingqiao Liu
ECCV 2026 [
Demo Page /
Paper /
Code]
Points-to-3D: Structure-Aware 3D Generation with Point Cloud Priors Jiatong Xia*,
Zicheng Duan*, Anton van den Hengel, Lingqiao Liu
CVPR 2026 [
Demo Page /
Paper]
VQ-VA World: Towards High-Quality Visual Question-Visual Answering Chenhui Gou*, Zilong Chen*, Zeyu Wang*, Feng Li, Deyao Zhu,
Zicheng Duan, Kunchang Li, Chaorui Deng, Hongyi Yuan, Haoqi Fan, Cihang Xie, Jianfei Cai, Hamid Rezatofighi
CVPR 2026 [
Demo Page /
Paper]
An empirical study on how video-LLMs answer video questions Chenhui Gou, Ziyu Ma,
Zicheng Duan, Haoyu He, Feng Chen, Akide Liu, Bohan Zhuang, Jianfei Cai, Hamid Rezatofighi
CVPR 2026 [
Paper]
EZIGen: Enhancing zero-shot personalized image generation with precise subject encoding and decoupled guidance Zicheng Duan, Yuxuan Ding, Chenhui Gou, Ziqin Zhou, Ethan Smith, Lingqiao Liu
BMVC 2025 [
Demo Page /
Paper /
Code]
Training-Free Motion-Guided Video Generation with Enhanced Temporal Consistency Using Motion Consistency Loss Xinyu Zhang,
Zicheng Duan, Dong Gong, Lingqiao Liu
BMVC 2025 [
Demo Page /
Paper]
Let Your Video Listen to Your Music! Xinyu Zhang, Dong Gong,
Zicheng Duan, Anton van den Hengel, Lingqiao Liu
ACM MM 2025 [
Demo Page /
Paper]
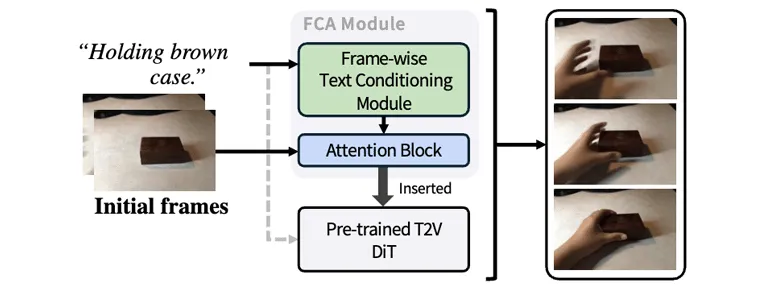
Frame-wise Conditioning Adaptation for Fine-Tuning Diffusion Models in Text-to-Video Prediction Zheyuan Liu, Junyan Wang,
Zicheng Duan, Cristian Rodriguez-Opazo, Anton Van Den Hengel
TMLR (2025) [
Paper]
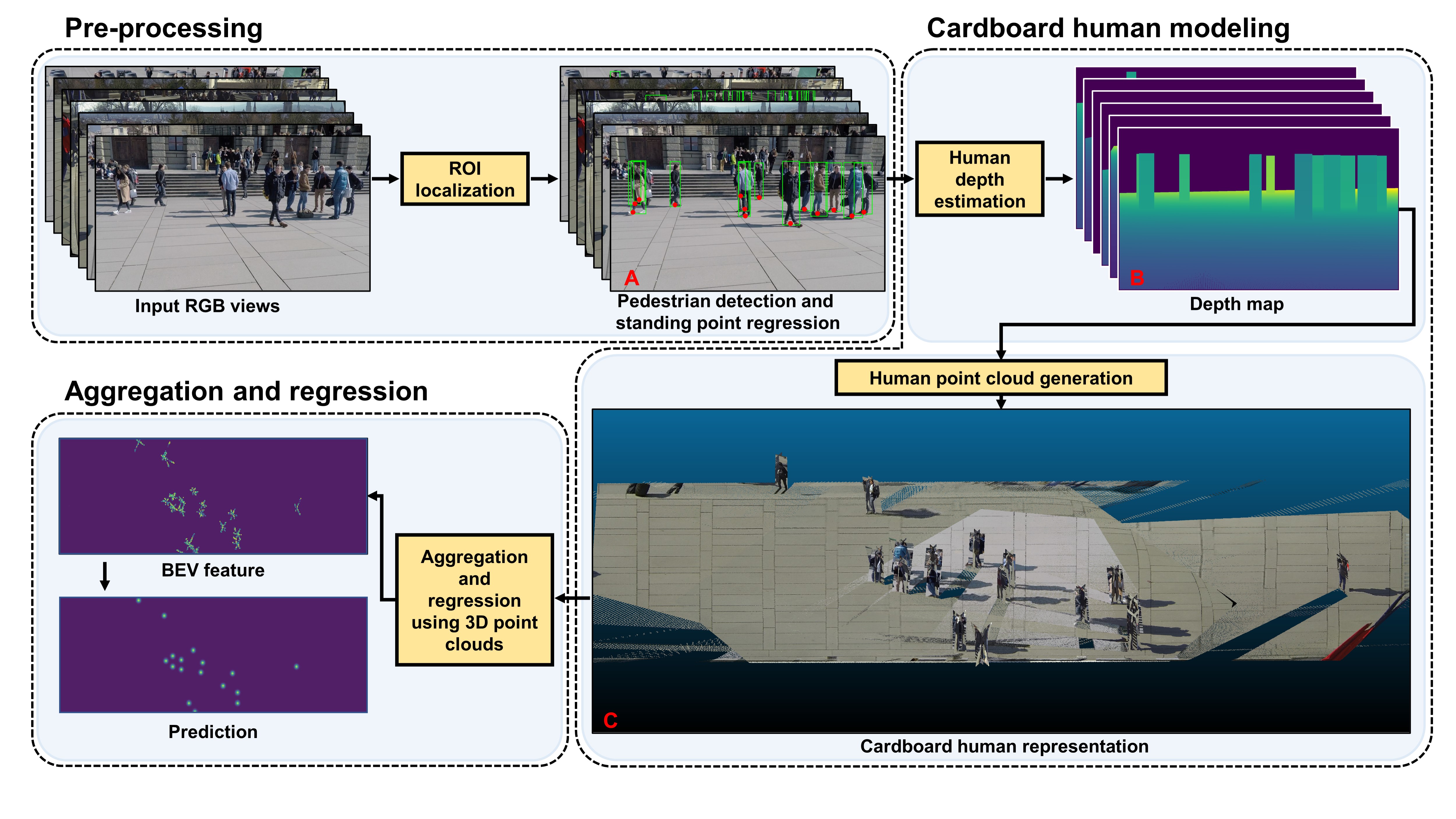
Multiview Detection with Cardboard Human Modeling Jiahao Ma*,
Zicheng Duan*, Liang Zheng, Chuong-Nguyen
ACCV 2024 [
Paper /
Code]
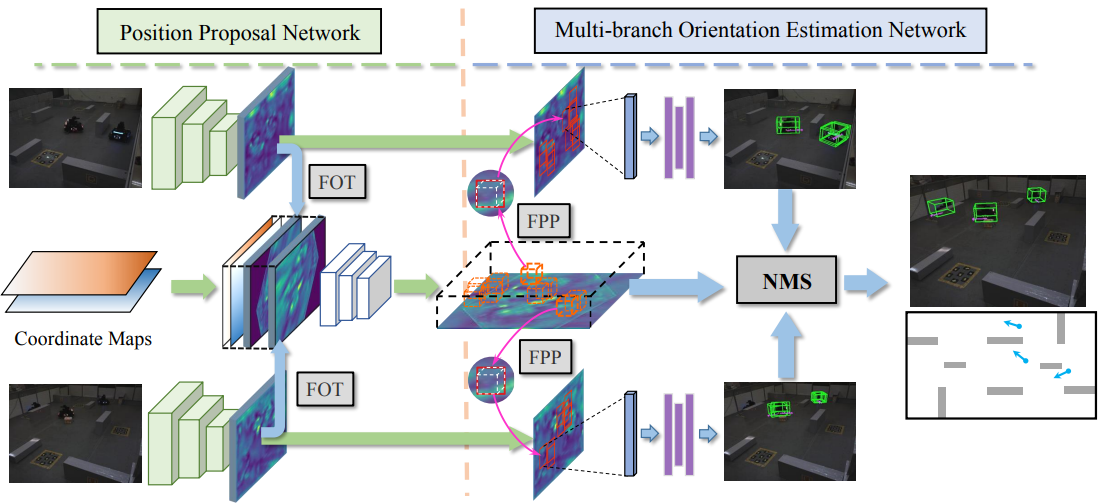
Voxelized 3D Feature Aggregation for Multiview Detection Jiahao Ma, Jinguang Tong, Shan Wang,
Zicheng Duan, Liang Zheng, Chuong-Nguyen
DICTA 2024 [
Paper /
Code /
Dataset]
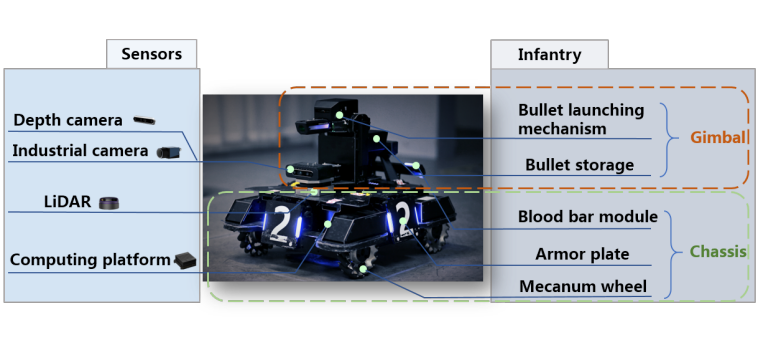
Neurons perception dataset for RoboMaster AI challenge Haoran Li,
Zicheng Duan, Jiaqi Li, Mingjun Ma, Yaran Chen, Doingbin Zhao
IJCNN 2022 [
Paper /
Code]
MVM3Det: A Novel Method for Multi-view Monocular 3D Detection Haoran Li,
Zicheng Duan, Mingjun Ma, Yaran Chen, Jiaqi Li, Doingbin Zhao
arXiv preprint (2021) [
Paper /
Code]
Projects
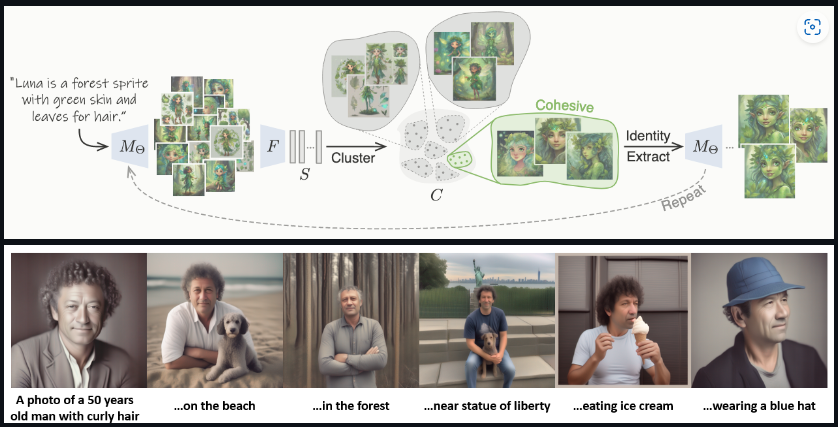
Unofficial implementation of paper The Chosen One Selected as the official implementation by the author.
[
Paper /
Code]
Competitions
ICRA 2021 Workshop RoboMaster Competition
Team Neurons, ranks 6/26
Academic Services
Reviewer: CVPR’26, AAAI’25, DICTA’25, NeurIPS’24, ICASSP’24
Talks