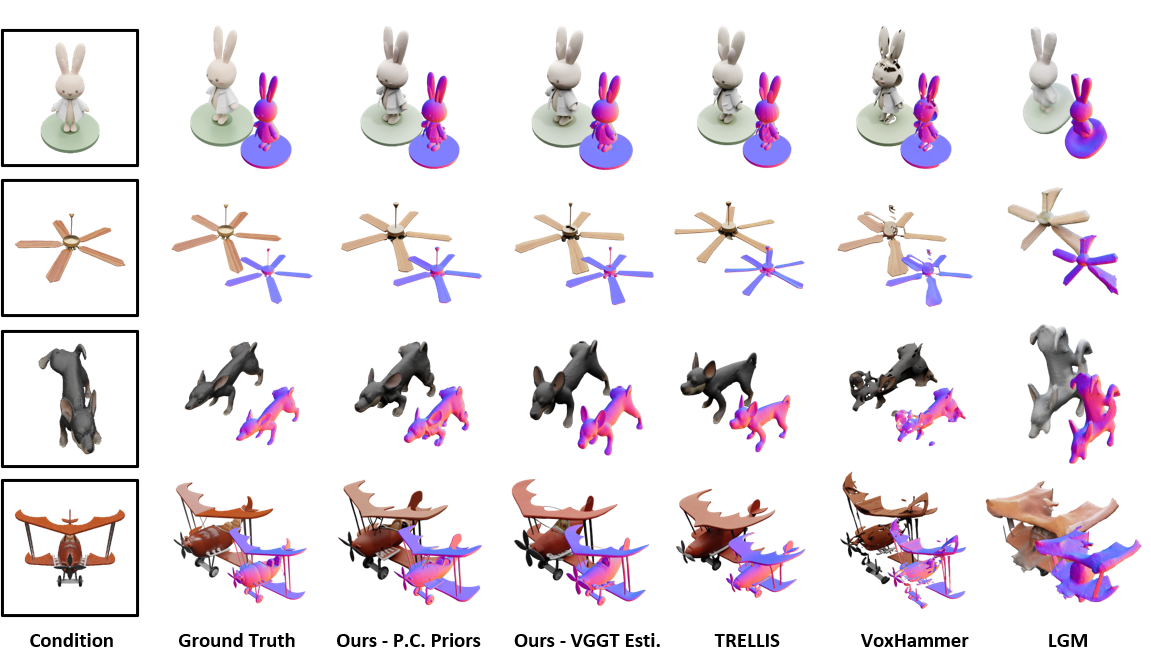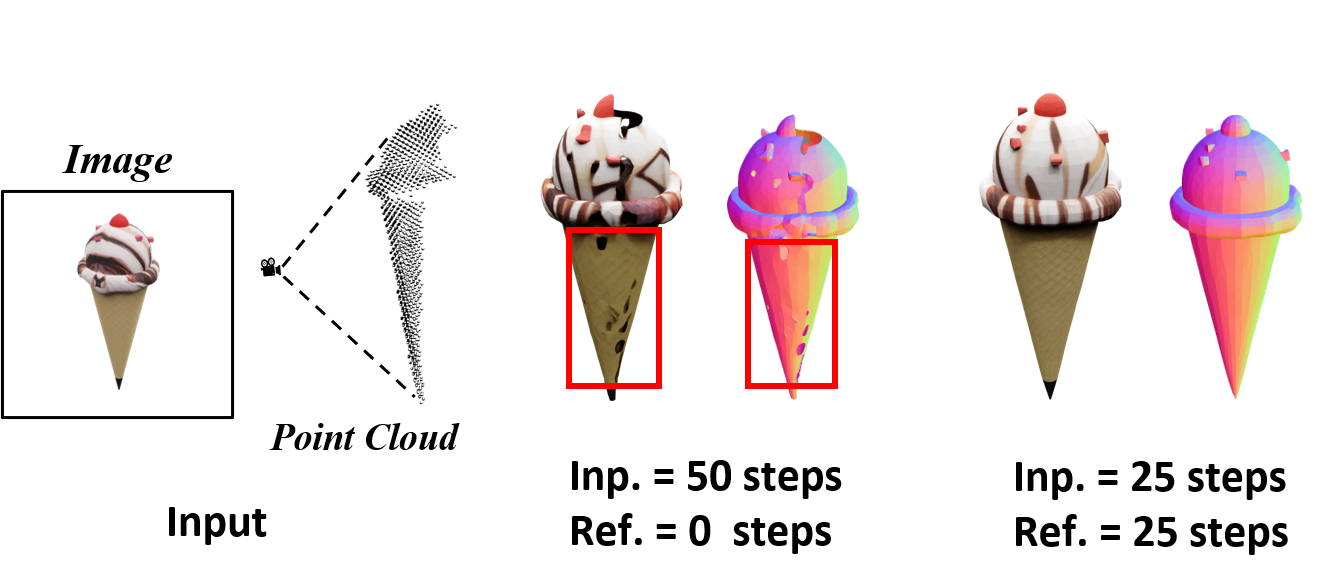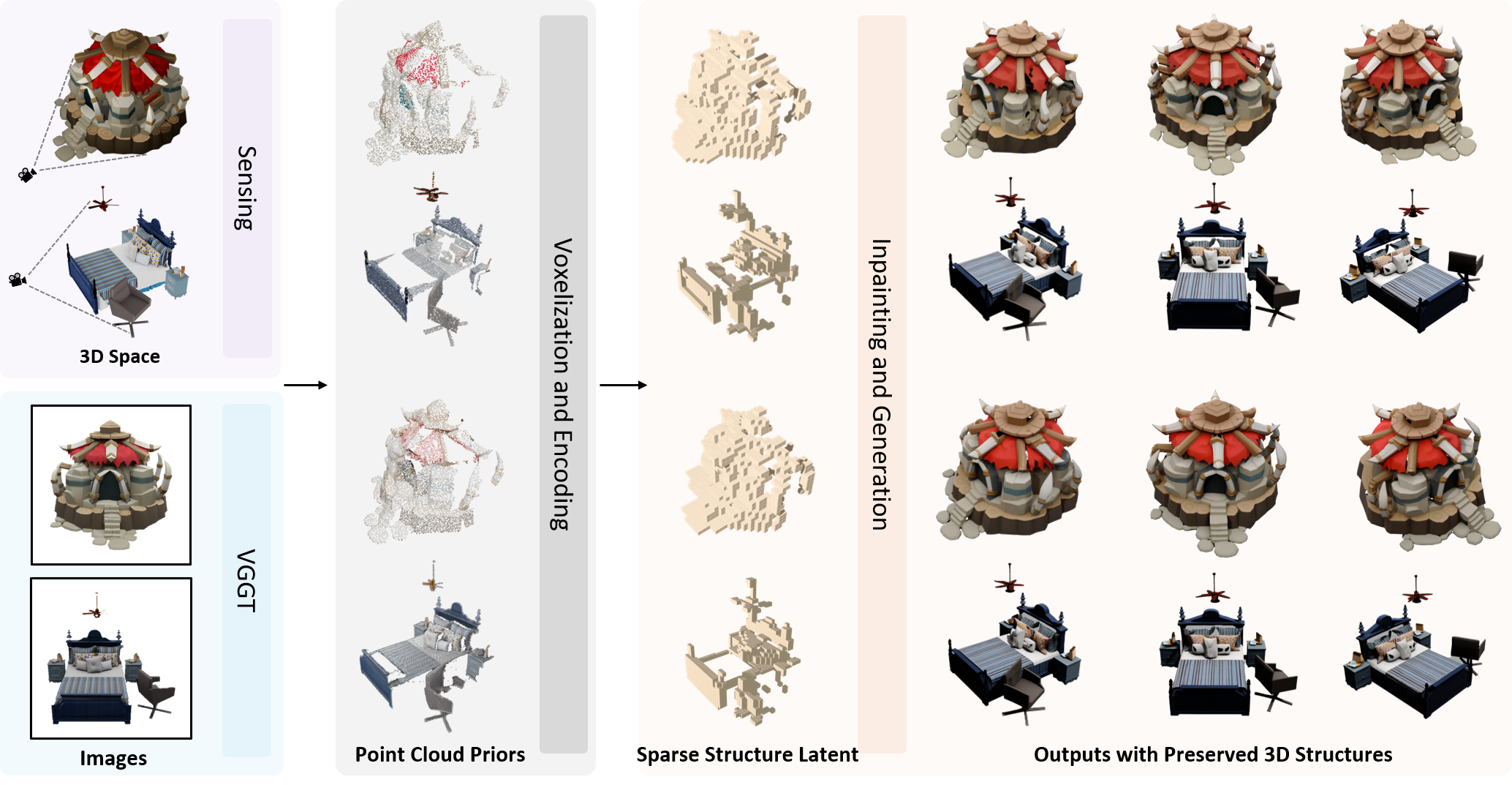
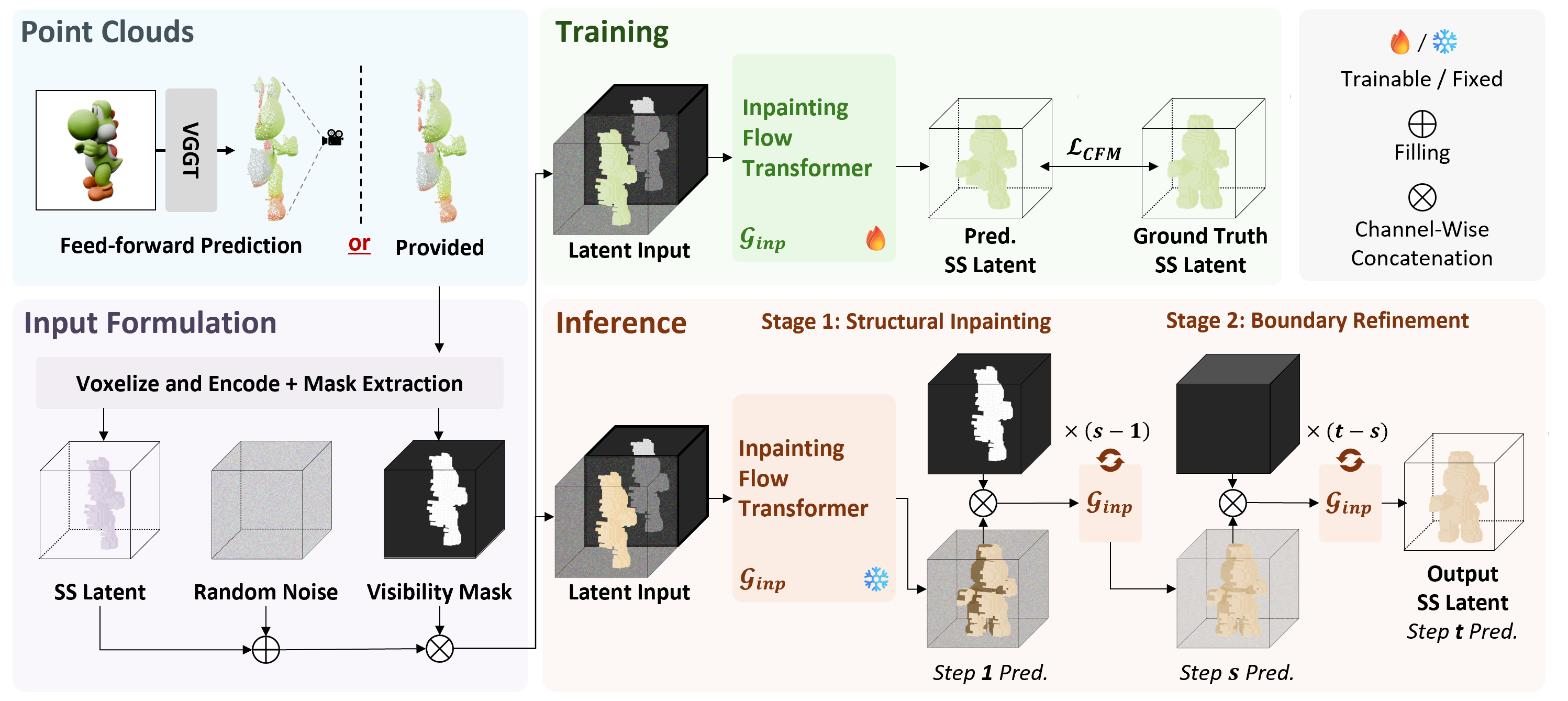

| Method | Rendering | Geometry | ||||||
|---|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM(%)↑ | LPIPS↓ | DINO(%)↓ | CD↓ | F-Score↑ | PSNR-N↑ | LPIPS-N↓ | |
| GaussianAnything | 20.08 | 89.31 | 0.183 | 26.74 | 0.084 | 0.513 | 20.99 | 0.199 |
| Real3D | 19.55 | 90.65 | 0.169 | 27.65 | 0.065 | 0.574 | 21.31 | 0.178 |
| LGM | 20.55 | 89.98 | 0.181 | 23.45 | 0.075 | 0.487 | 20.04 | 0.202 |
| VoxHammer (3D Inversion) | 20.51 | 90.01 | 0.123 | 15.10 | 0.046 | 0.724 | 20.28 | 0.158 |
| TRELLIS | 21.94 | 91.46 | 0.105 | 7.82 | 0.034 | 0.832 | 23.81 | 0.105 |
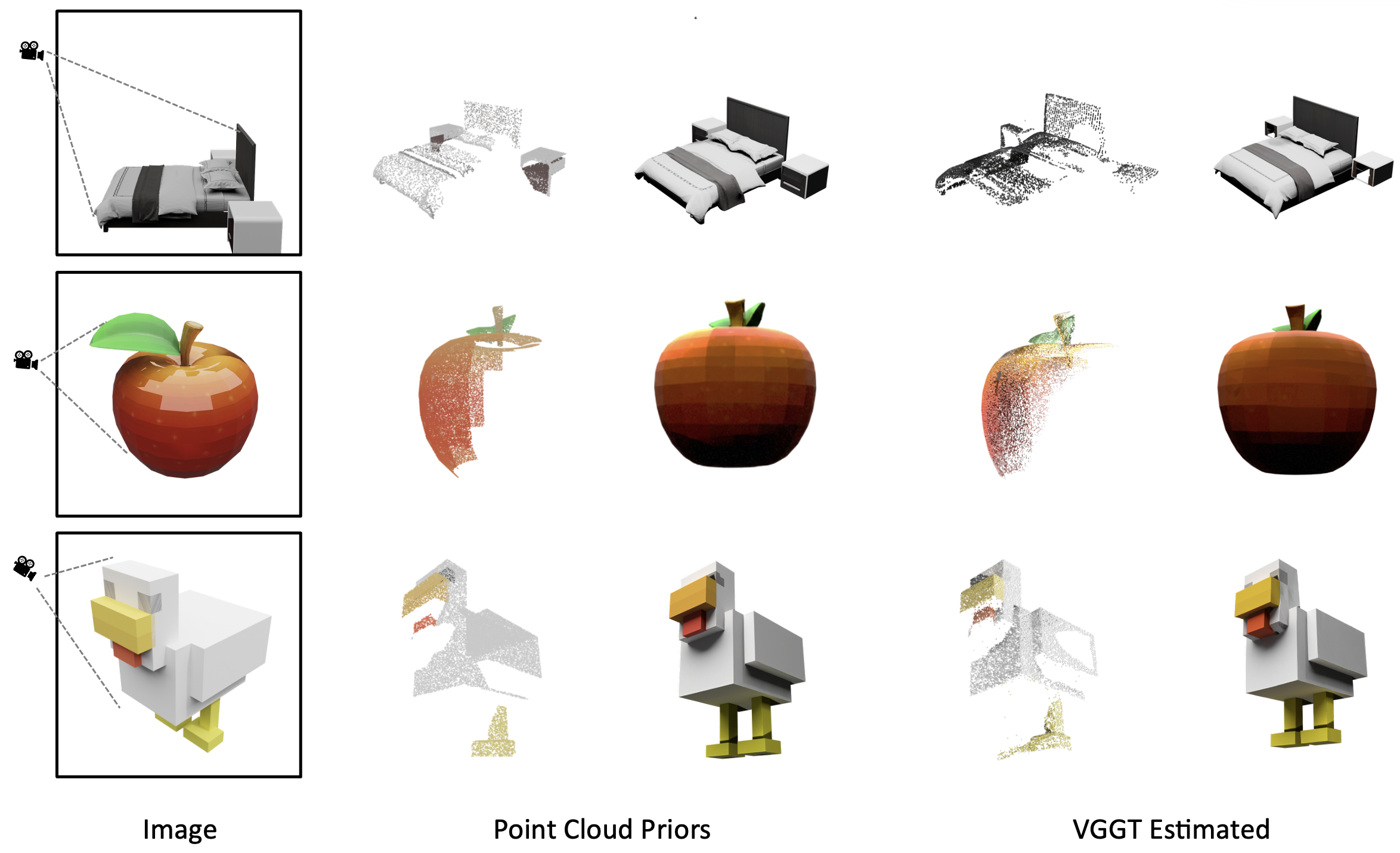
| Points-to-3D (Ours-VGGT Esti.) | 22.55 | 92.09 | 0.088 | 7.37 | 0.024 | 0.881 | 24.53 | 0.085 |
| Points-to-3D (Ours-P.C.Priors) | 22.91 | 92.83 | 0.070 | 7.29 | 0.013 | 0.964 | 27.10 | 0.053 |
Table 1. Comparison on single-object generation on Toys4K dataset. We showcase the performance of our method in two scenarios: one where explicit point cloud priors are provided, and another where point clouds are inferred from condition images using VGGT.